I beg to differ. ![]()
Clearly you are going on about the testing itself, while @404error whom I quoted is worried about the wearout.
In any way there is no issue here at all.
I beg to differ. ![]()
Clearly you are going on about the testing itself, while @404error whom I quoted is worried about the wearout.
In any way there is no issue here at all.
Thanks you there Falzo for clarifying that for me. Much appreciate that of you. <3
@Falzo I’m focused on the wearout but I understood @Friendly concern, I’m just uneducated myself to know the degree of importance of either points (wearout and ability to test).
I appreciate all thehlp you guys are giving me, this is an opportunity for me to learn. Sol here goes another questions.
Q: Doesn’t RAID 1 means that both HDs have the same info on them?
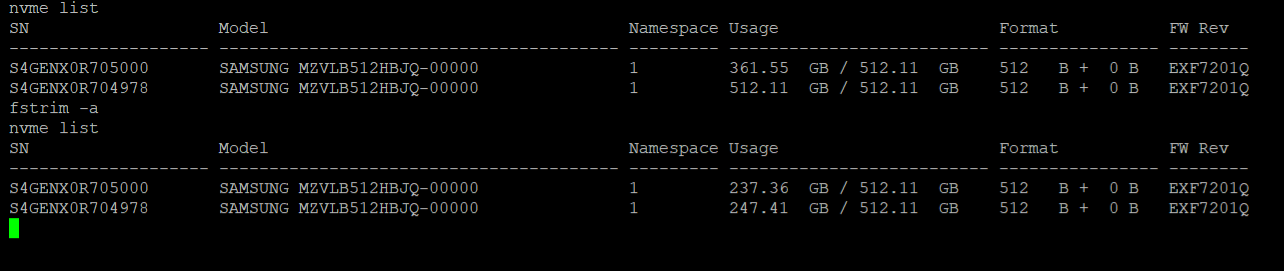
But nvme list comes up with
Node SN Model Namespace Usage Format FW Rev
/dev/nvme0n1 S4GENX0R705000 SAMSUNG MZVLB512HBJQ-00000 1 361.54 GB / 512.11 GB 512 B + 0 B EXF7201Q
/dev/nvme1n1 S4GENX0R704978 SAMSUNG MZVLB512HBJQ-00000 1 512.11 GB / 512.11 GB 512 B + 0 B EXF7201Q
Shouldn’t both disks have sensibly the same storage use?
@Andrei You mean to submit a ticket with you guys? if yes, I don’t think its needed considering that from what I’m understanding none of this points out to be an actual issue, other than my own lack of education on the matter.
Not neccessarily. Especially soft raid via mdadm is on a different layer and has nothing to do with the wearout, as the disks could have been used before that differently. Also even if they had been in the very same raid-1 from the beginning you might still see differences in writes and especially reads (though probably not as large as on yours right now)
For the nvme list, I have to admit I am not familar with it, however I also assume the ‘usage’ there might be measured quite differently compared to the real usage, depending on the layer this is taken. Block level vs file system and so on.
Still confused. I understand disks wearout can be different but what the avalable space not being mirrored is counter intuitive to me.
from what I see on one server, i have 2 disks, boths have 512.11GB. they are on RAID 1.
YET, Disk 1 had 361.54GB our of the 512Gb in usage while disk 2 has 512/512 ?! da heck… or is this usage something different than actual data?
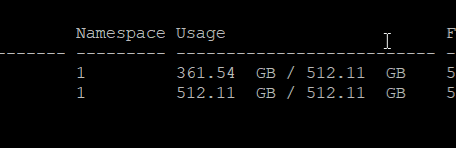
Yes. Run fstrim -a and check the usage again.
As said before, I think nvme list measures on the block level. That means data deleted in the file system might still occupy blocks and count there, while not being counted in the filesystem anymore.
Also did you trigger the resync yet?
Results.
Still not quite the same usage but its similar. How exactly did this work?
I was afraid to as I have sites live.
But I0’ve been playing on another server, that for some reason can’t get ApisCP to install a cert on… i’ll try there.
Actually this second server is exactly the one that had those prior issues… so glad its a playground for the moment.,
think of it as different layers on top of each other.
one is the nvme itself which has a specific amount of blocks of a certain size. it can measure how many of these block are filled with data - yet it does not know if that data means anything. just that there is something.
another layer is your filesystem this manages files as the name says and measures the sum of your files. if a file now gets deleted it will not show up in that sum anymore. however, deleting a file in the filesystem does not automatically mean, the data is actually erased completely, but usually the filesystem will only remove the meta data aka the references for it. that’s why you eventually can restore deleted files to a certain extend.
the underlying block level of the nvme does not know anything about deleted files, it will still see the blocks filled with the data of that deleted file. you actually need to pass through that information, so it is made aware of the freed up blocks. fstrim simply is one way to do that… and only afterwards the blocks used by deleted files will be properly marked as free for the block layer as well.
I think there will always be differences if you look at the block level, even with raid-1 and that is nothing to worry about after all. data get read and written all the time.
Your drives are more than fine, below average wearout and no media errors. Hetzner would definitely not be replacing those any time soon.
Here’s what I got on one of my servers:
Now those look bad, and would qualify for a replacement on most providers.
Then they need to compensate for explaining how the disks are still very test “able”.
Just because a disk not “on it’s way out” doesn’t means it shouldn’t be replaced. MOST manufacturers would happily RMA the disks if S.M.A.R.T didn’t worked on them for instance.
So I expect providers do the same.
maybe it would be better to check the output of smartctl -a directly per NVMe then, instead of relying on that little icon from the monitoring there. not sure, what exactly this is supposed to stand for.
as far as I understand that’s from the monitoring, right? so what if smartmontools isn’t installed at all. or there simply hasn’t been any smart test run on the disc so far?
It’s hetrixtools.
My understanding is that it uses GitHub - linux-nvme/nvme-cli: NVMe management command line interface. which I installed on the server prior of installing the Hetrixtools server agent.
Are you refering to…?
https://www.hostakers.com/kb/how-to-install-smartctl-utility-on-centos-7/
That looks bad. Why wasn’t it replaced? 2.5 lifetime uses… sounds like those HDs already made up for their existence.
Yes. Just yum install smartmontools and then run smartctl -a /dev/nvme... for your disk to get a much more thourough output.
You do not neccessarily need the smartd service.
Don’t need them replaced yet, not until they start failing. They’re both in RAID1 and the server is not used in production and can withstand downtime and/or data loss.
To add to that, for ssd or nvme I’d rather look at how many spare cells are used or left and not just the wear out. If there is nothing going on there usually ypu do not need tp be afraid.
Depends on your workload and how many GB written per day you burn though. ![]()
Keywords “not just”. I am still gonna request a replacement once the counter is close to 100% regardless if there is usage on those spare cells and etc.
On production systems you really need to replace hardware when it’s meant to be replaced. In the senses of SSDs, that’s when their T/PBW are up (assuming there not other problems associated with the device).
Firstly what does this have to do the thread? I am genuinely so confused here.
Also even in HDDs’ environments RAID0 are HUGELY not used anymore in place of other MUCH more favorable options, beefer OSes, etc.
So unless you like work for some companies still using 146GB SASes you don’t need to typically worry about doing a RAID0 for it’s benefits.