My sites hosted on VirMach is facing issues for more than an hour. It goes offline for 1 or 2 minutes and then come back online.
LET is facing similar issues and so is VirMach billing panel and site. Looks like a DDos attack. Or may be issue with ColoCrossing?
Due to this downtime I have suffered a loss of around $1993738 x 0 = 0 dollars. This is unacceptable because I am paying $1 per year for this VPS (BF 2018 deal) and I expect 100% uptime.
Update - We are continuing to work on a fix for this issue.
Jun 24, 11:43 UTC
Identified - We have identified a possible route leak impacting some Cloudflare IP ranges and are working with the network involved to resolve this.
Jun 24, 11:36 UTC
Investigating - Cloudflare is observing network related issues.
Jun 24, 11:02 UTC
Half of the internet is down. A $clueless_company is leaking the whole internet routing table to the clueless Verizon, who redistributes it to a lot of ISPs.
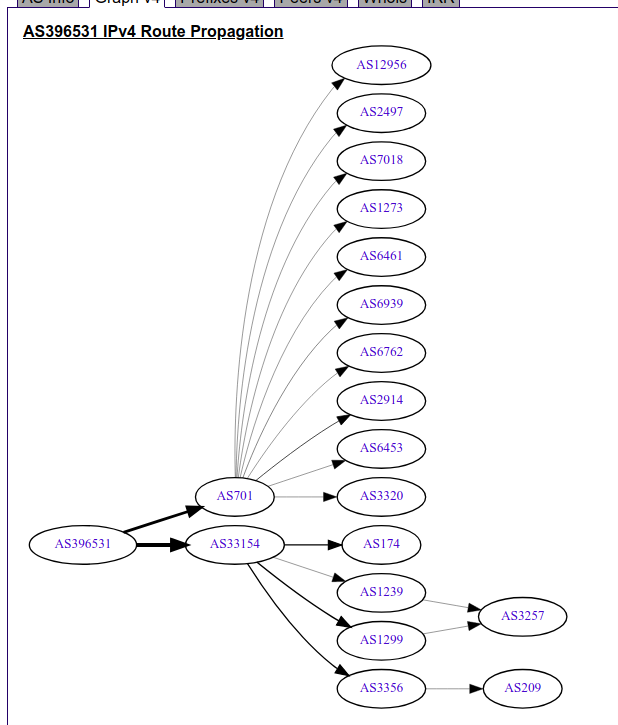
We can see that a $clueless_company (AS396531 / Allegheny whatever) gets internet connectivity through two providers (called upstreams in the network speak): Verizon (AS701) and DQE Communications (AS33154).
So what does “get connectivity” exactly entail? $clueless_company receives a bunch of routes - in fact, probably the whole internet routing table (which is around 800k routes at the moment) from both providers. Their router imports a routing table from both of these providers and then chooses best routes based on several factors.
Now this communication/exchange of routes (which happens over a protocol called BGP) goes both sides. Basically as a company, you want to have some IP space of your own too. So in order for the world to be able to reach your IP space, you need to export routes for this IP space to your upstreams.
Thanks to the magic of routing, every router on the internet knows that in order to reach your IP space, they need to go either through Verizon or DQE. Great!
BUT. You are supposed to FILTER what you export!!! So essentially instead of only exporting their 1 prefix (IP block/range) or so, they did this:
To put it in words - they took everything DQE provided them and swiftly exported that to Verizon. Verizon decided to play an exhibitionist and propagated this to the rest of their peers - basically all other Tier 1 ISPs ( some of which accepted it - I know at least TATA, Cogent, Telia did) and their customers.
Which meant that half of the internet now learned that in order to reach e.g. CloudFlare or OVH or whatever, they can go through Verizon → $clueless_company → DQE.
To be honest, I’m not even mad at the $clueless_company. They made a mistake, and mistakes happen.
Who I’m pissed off at is Verizon. Their multiple faults resulted in this disaster.
They didn’t filter $clueless_company
They didn’t put a prefix count limit on $clueless_company
Their NOC did exactly nothing to mitigate this issue
//EDIT: Decided to make it into a blog post. Check it out if you want slightly more details
Perfect, that makes far more sense than what I was researching. Thank you for taking the time to explain that! Yeah, shit happens, but damn Verizon should sort their shit out.
Similar, but I think the Pakistan incident was intentional to cut off YouTube traffic and it got leaked out because of a Hong Kong telecom company not filtering it out.
Probably more similar to when European mobile internet traffic was rerouted through China earlier this month due to another BGP mistake/leak.
There are subtle differences. The Pakistan incident was a “BGP Hijack”, this was a “BGP Leak”.
What’s the difference? It’s simple really.
When you do a BGP Hijack, you (either intentionally or by accident) claim that “Hey internet, IP address 1.3.3.7 is mine. Send traffic for this to me!”
This can potentially be used by malicious actors to pretend they’re popular sites (and do phishing; steal login credentials), to block DNS, to assume a block of IP addresses for sending spam…
With a BGP Leak, you (mostly accidentally, there are not many illegitimate purposes for this) claim this: “Hey internet, you can reach Google through me!”
Unless you want to snoop on traffic (and pay outrageous bandwidth bills depending on leak size), there are no illegitimate purposes for this. You just redirect traffic through yourself.
In theory, this shouldn’t affect reachability - it just increases latency. The problem is when (as we’ve seen today) the port capacity is small. We can assume all of CloudFlare’s (and others’) traffic tried to flow through something like a 10 gigabit port. This causes the port to get overwhelmed and introduces near 100% packetloss.
A BGP Hijack is much harder to pull off since there are mechanisms in place (and sometimes working ) which limit, or completely prevent any impact.